In Laravel projects, a lot of issues come from non-Laravel mistakes, database structure is one of those. In this tutorial, we will cover the most typical mistakes devs make when structuring DB in Laravel.
For example, have you ever encountered an issue with fields not being nullable? Or maybe you had problems with relationships being incorrect type?

Don't worry - you are not alone! Let's cover the most typical mistakes and how to solve them.
When defining the relationships, some developers forget to add foreign key definitions to the database. Let's look at an example:
Schema::create('clients', function (Blueprint $table) { $table->id(); $table->string('first_name'); // ...});Schema::create('orders', function (Blueprint $table) { $table->id(); $table->unsignedBigInteger('client'); // ...});As you can see, no ->foreign() here.
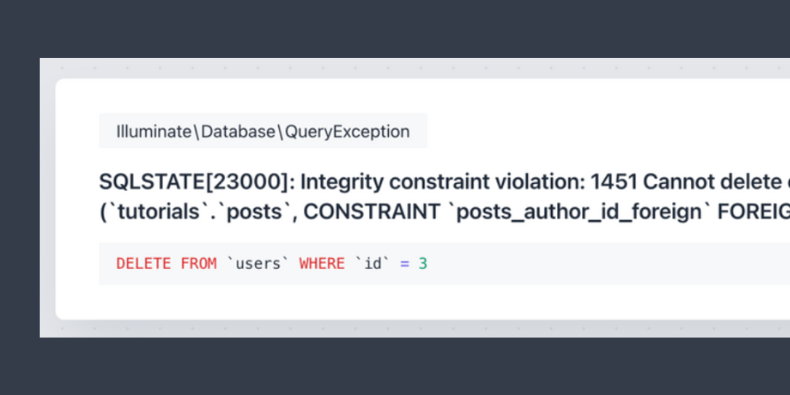
This works fine for the most part, but once we have some clients and orders in our system - deleting a client will cause an issue:
If we look at our database, we can see that we still have an order with our deleted client:

This issue happened because our database has no idea what to do in that scenario. All it thinks of - is that we have a number in our client column, which is not tied to anything.
You can solve this issue with foreign keys, as this will tell the database to check if the client exists before doing anything with the client_id column. Let's look at an example:
Schema::create('orders', function (Blueprint $table) { $table->id(); $table->unsignedBigInteger('client_id'); $table->foreign('client_id')->references('id')->on('clients'); // ...});Now we will do the same action - attempting to delete our client:

This time, our deletion has failed, but our Orders table is still working:
Why did this happen? Well, in the database, we have a constraint added. This limits what action can happen with our parent resource.
In our case, we can only delete a Client after first deleting all their orders. Of course, you need to handle this error with a try-catch block, but this provides a better development experience.
Even if you forget about this - Database has your back! It might break the user experience, but this will prevent bigger collapses in your system.
There is one small thing to note here - column naming. In our example, we used client, which is okay to use, but standard practice is to use the singular form of the table name suffixed with _id. So, in our case, it would be:
Schema::create('orders', function (Blueprint $table) { $table->id(); $table->unsignedBigInteger('client_id'); $table->foreign('client_id')->references('id')->on('clients'); // ...});Or, shorter:
Schema::create('orders', function (Blueprint $table) { $table->id(); $table->foreignId('client_id')->constrained(); // ...});While this is a personal preference - it does help you to understand what the column is for. If you have client - you might think it's some identifier for the client (especially in bigger databases), but if you have client_id - you know it's a foreign key to the clients table. A quick look at a database like this - points us in the right direction:
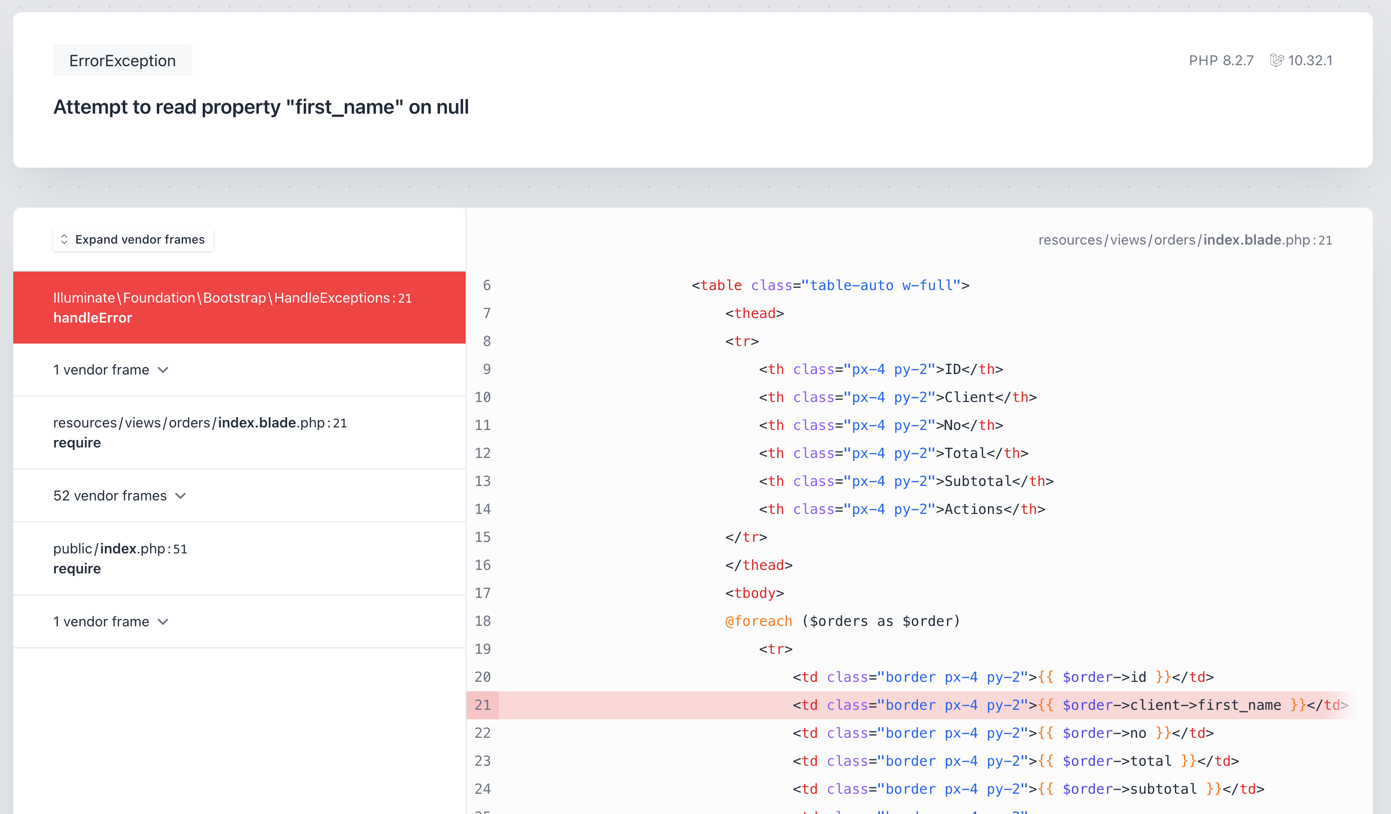
Another common issue with Database design is wrong column types, like creating an int field but needing to add floats later on.
One specific case is quite common - varchar fields with comma-separated values instead of using relationships. Let's look at an example:
Schema::create('orders', function (Blueprint $table) { $table->id(); $table->string('client_id'); // ...});This seems fine, right? Well, it probably is okay until you have something like this:

What do we have here? We have a list of related IDs in the format of a string. We have seen this used as a way to have one-to-many relationships.
For example, we would expect our order to have multiple Clients. But this is different from how it works. This is just a string, and if you try to use it as a relationship:
Model
// ... public function client(){ return $this->belongsToMany(Client::class);} // ...You will get an error like this:

Even if you try to use this as a belongsTo relationship like this:
Model
// ... public function client(){ return $this->belongsTo(Client::class);} // ...You will still have an issue where incorrect data will be loaded:

As you can see, it tries to find the client with an ID of 1, 2, 5, 9 or 2, 3, 1, 4 and not the actual IDs. This is because Databases treat this as a string and not as a list of IDs. So what is the better option? Correctly defining this relationship and using a correct column type:
Schema::create('client_order', function (Blueprint $table) { $table->foreignId('client_id')->constrained('clients'); $table->foreignId('order_id')->constrained('orders');});This will produce a Database schema like this:

This helps you avoid common mistakes and also allows you to control your data in a better way.
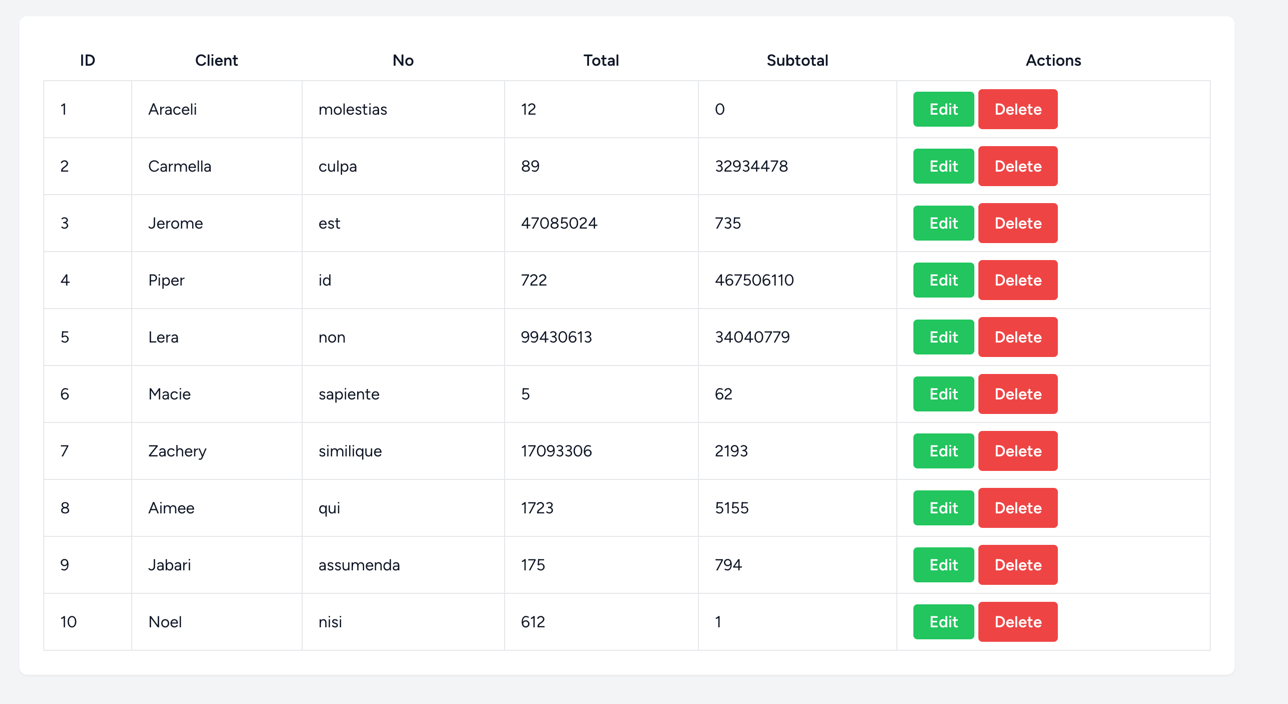
Indexing in Databases is often looked at as something that has to be done in massive projects, so they are skipped at the initial step. But what does it really do to our systems? Let's look at an example:
And we want to load the order count for each of our Clients to display it on our table. This seems fine, as we can use code like this:
Migration
Schema::create('orders', function (Blueprint $table) { $table->id(); $table->unsignedBigInteger('client_id'); // ...});Controller
$clients = Client::withCount('orders')->paginate(50);In this example, we ignored the index on our client_id in the orders table. Let's load the page and check the debug bar:

Looking closely, it takes 3.87s to load the count! That's A LOT OF TIME to do this kind of operation. Now let's try to add an Index to our client_id column:
Schema::create('orders', function (Blueprint $table) { $table->id(); $table->unsignedBigInteger('client_id'); $table->index('client_id'); // ...});And re-run the same code again:

As we can see now, this runs in 1.96ms - which is way faster than what we had before. This is because Indexes help us make a map (a lot of generalization here, but treat it like a directory of where to find what value in your database) of our data. This helps the database to run faster.
Laravel has a particular way to form many-to-many Pivot tables to auto-resolve them. Let's look at an example:
clients tableorders tableWhat should our Pivot table name be?
client_order
order_client
clients_orders
orders_clients
In this case, Laravel would expect it to be client_order, and if we follow that, we can define our relationship like this:
Client Model
public function orders(): BelongsToMany{ return $this->belongsToMany(Order::class);}Order Model
public function client(): BelongsToMany{ return $this->belongsToMany(Client::class);}Now, let's do an example where we have a different table name, in this case - client_orders. What will happen then? Well, our relationship will break:

Now, it is not such a big deal at the Database level, but on our Laravel side - we have to add a table name to our relationship:
Client Model
public function orders(): BelongsToMany{ return $this->belongsToMany(Order::class, 'client_orders');}Order Model
public function client(): BelongsToMany{ return $this->belongsToMany(Client::class, 'client_orders');}It doesn't seem like a big deal. Still, it is a lot of extra code to write (especially if you have a lot of Models), and it can be easily avoided by following the naming convention.
When defining a foreign key - we tend to ignore cascading actions and leave it as it is. But that causes another typical mistake to happen:
This mistake happens when we try to delete a User from our database, but this user has some Posts. And since we did not inform our database what it should do once this happens - it just throws an error.
To fix this, we can implement "OnDelete" actions, like cascade:
Schema::create('posts', function (Blueprint $table) { $table->id(); $table->foreignId('author_id')->constrained('users')->cascadeOnDelete(); // ...});Now, if we attempt to delete a User with Posts, it will also delete all the Posts. This is a handy feature, but you can also use other options:
cascadeOnDelete() - This will delete all related entries once the parent is deletedrestrictOnDelete() - This will throw an error if there are any related entries (this is the default behavior)nullOnDelete() - This will set all related entries to null once the parent is deleted (this requires the column to be nullable!)These options handle different scenarios, so you must choose the best one that fits your needs. But remember - always choose one of these options, as it will help you to avoid errors in your system.
Due to how the database works - the cascading actions will not cover Soft Delete models. Cascading only works with full deletes. So if you have a User with Posts and Soft Delete the User - the Posts will remain there.
Soft Delete is a Laravel feature, not a Database feature. So, if you want to delete all related entries, you must do it manually. There's also a package cascade-soft-deletes that can help you.
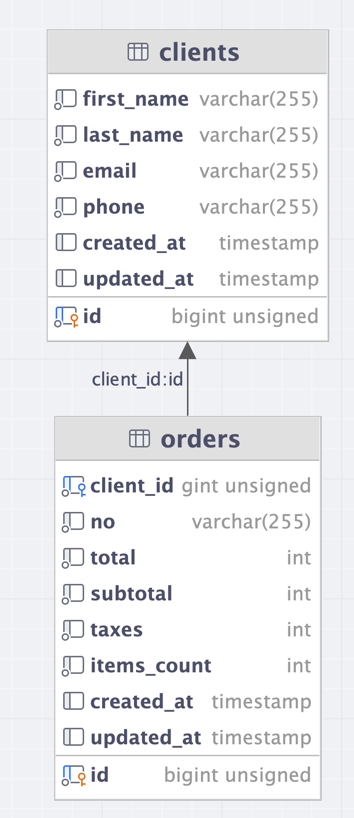
When starting a new database design, following Database Normalization is essential. But what does it mean in practice? What is normal in this case? Let's look at a few common mistakes that should be avoided.
Take a look at this database example:

Do you see something wrong with it? If yes - fantastic, you have a good eye! If not, here's the list:
To normalize this table - we have to perform a few actions, so let's talk about the decisions we had to make:
hasMany. We will gain faster filters and more control over our queries.belongsToMany relationship.belongsToMany table. This will allow us to quickly retrieve all products within a specific tag.belongsToMany relationship, as one supplier can have multiple products, and one product can have multiple suppliers.belongsToMany relationship, as one carrier can have multiple products, and one product can have multiple carriers.With all that done, we can work with our data more efficiently. We can now easily find products with specific SKUs, Category, Tag, Supplier, or Carrier. We can also easily find all products with a particular Supplier or Carrier.
This is a lot of flexibility that we gain by following normalization rules. And I'm not even talking about the performance gains you will get - as you will have to do fewer full-text searches!
Here's what our database can look like after normalization:

And while this required a lot more tables - everything is now in its own place, and we can efficiently work with our data in any way we want.
One of the biggest misconceptions about databases is timezones. People think you need to set the timezone in your application, and everything will work.
But often, we must remember that having the same settings for our database engine and our Laravel application is mandatory.
Let's look at an example:
Europe/Vilnius timezone, set in the DB settingsUTC timezone, set in the config/app.php
Running an update like this:
update posts set published_at = now() where id = 1And then doing the same with Laravel:
Post::where('id', 12) ->update([ 'published_at' => now() ]);Will produce different results:

1 has Europe/Vilnius timezone as it was created in the database by running a query there12 has UTC timezone as it was created by the Laravel applicationThis can lead to many issues and things that happen at unexpected times. For example, if this was a notification to be pushed out - we would have 2 different outcomes.
Now, if we set the timezone on our application and database to be the same - this will never be an issue.
Note: Avoid changing your Database or Laravel timezone settings if you already have a live application, as it will lead to incorrect times.
When creating pivot tables, we often skip adding timestamps or primary keys. This is because we think that we don't need them. But there may be cases when it's not true. Let's look at an example:
In our system, we have products and categories. Product has many categories - the typical scenario that looks like this in our database:

It works as we would expect. But today, a new requirement came - we need to sort the categories by the time they were attached. And now - we have an issue. We have no idea when these categories were added. So what can we do here? Well, we can add timestamps to our pivot table:

Now, we can order our categories by the time they are added. This dramatically improves the potential for data access and control in your application.
A similar thing happens with primary keys - they prevent an issue where if you accidentally create a duplicate entry - you won't be able to delete it anymore. Adding a primary key gives your records an identifier and prevents this issue.
Note: While it is debatable if you should use timestamps in pivot tables - they solve more problems than they create. So, we recommend using them for all pivot tables. If not for ordering - you still can see when something was attached to something else.
Often, we see people using Laravel Form Validation to validate if a field is unique like this:
$request->validate([ 'invoice_number' => ['required', 'unique:invoices'],]);And while it is a good thing to have - this comes with a drawback. Our database is not protected!

Why is that? Well - this only protects us from the submission of forms.
But what if someone adds the entry directly to the database like we did. The same applies if you create a unique table entry using Model::create() - there is no protection. To solve this, we need to add a unique index to our database:
Schema::create('invoices', function (Blueprint $table) { $table->id(); $table->string('invoice_number')->unique(); // ...});Once this is done - it will not matter if the form is submitted or you are trying to insert the data directly into the database - it will always check if the value is unique. Let's look at this example from our database query:

And if we try to do that with our Model:
Invoice::create([ 'invoice_number' => '2023-11-000001']);We will still get a database error:

Note: This also prevents a race condition where two or more people attempt to simultaneously create the same unique value.
One mistake that can send you into a giant rabbit hole is forgetting to make fields nullable. We often think that all fields are required, but there are a few cases where this might not be true. Let's look at both of them:
When you want to add a relationship to an existing site, remember that it is usually constrained by a foreign key. This means that if the relationship is not nullable, you will see issues like this in your migrations:

Why did this happen? Well, we already have data in our system, but now attempted to add another relationship like this:
Migration
Schema::table('clients', function (Blueprint $table) { $table->foreignIdFor(ClientTag::class)->constrained();});This causes a problem with our old records. As we have data already:

They will not have this relationship in place (as you can see, it failed and has 0 there...), so we have to make it nullable:
Migration
Schema::table('clients', function (Blueprint $table) { $table->foreignIdFor(ClientTag::class)->constrained(); $table->foreignIdFor(ClientTag::class)->nullable()->constrained();});Now, it will allow our migration to pass without triggering any errors. This common mistake can be easily avoided by ensuring all new relationships are nullable. If that is not possible, add a default value to your fields.
Another issue that can be resolved with nullable fields - import failures. This often happens due to somehow malformed data in our CSV files. For example, if we have a CSV file like this:
id,first_name,last_name1,John,Doe2,Jane,Doe3,Tom,4,,JohnsonYou can try to import it into your database, but you will get an error like this:

This happened because of two things:
First - we have first_name and last_name as non-nullable fields in our database:
Schema::create('clients', function (Blueprint $table) { $table->id(); $table->string('first_name'); $table->string('last_name'); $table->timestamps();});Second - we have our import script that handles missing values as null:
private function importData(array $row): void{ Client::create([ 'first_name' => $row['first_name'] ?: null, 'last_name' => $row['last_name'] ?: null, ]);}Both of these issues can be solved by making our fields nullable:
Schema::create('clients', function (Blueprint $table) { $table->id(); $table->string('first_name'); $table->string('last_name'); $table->string('first_name')->nullable(); $table->string('last_name')->nullable(); $table->timestamps();});Re-running our import script will now work as expected:

That's it. Adding nullables is a great way to avoid issues with your database. And if you think that empty values can be set to string - look at our following example!
Have you ever looked at a database and seen something like this?
![]()
And then you visit migrations in the hope of understanding what is going on, but you see this:
Schema::create('posts', function (Blueprint $table) { $table->id(); $table->foreignId('author_id')->constrained('users')->cascadeOnDelete(); $table->string('title'); $table->text('content'); $table->string('summary'); $table->string('excerpt'); $table->string('seo_title'); $table->string('seo_description'); $table->string('seo_keywords'); $table->datetime('published_at')->nullable(); $table->timestamps();});And you realize that all fields should have values, but none of them do. And while this works - it is not recommended as this often means - you need better database design. It often hides issues within the system, making it harder to use. Solving this is as simple as adding ->nullable() to your fields:
Schema::create('posts', function (Blueprint $table) { $table->id(); $table->foreignId('author_id')->constrained('users')->cascadeOnDelete(); $table->string('title'); $table->text('content')->nullable(); $table->string('summary')->nullable(); $table->string('excerpt')->nullable(); $table->string('seo_title')->nullable(); $table->string('seo_description')->nullable(); $table->string('seo_keywords')->nullable(); $table->datetime('published_at')->nullable(); $table->timestamps();});And now, you have a database that expects columns to contain empty values. Even future developers will be happy as there is no more need for ->update(['content' => '']) hacks in your code. It can just be skipped, and it will be handled by the database itself.
The last mistake we see constantly in forums - rushed database designs. And while this sometimes is unavoidable - it still has repeating patterns:
These mistakes do not come from a lack of knowledge. Instead, it all comes from a viewpoint. For example, there is a big difference in choosing a relationship type. You might get away with belongsTo today, but tomorrow you might need belongsToMany. And if you did not plan for that - you will have to rewrite a lot of code. The same goes for any fields and tables in your database. Here's what we recommend:
These are just a few examples, but they all point to the same thing - spend more time planning and playing with pseudo queries to see how things feel.
.png-674b52556562e.jpg)

.png-674b519a8f3bb.jpg)
.png-674b5257ead23.jpg)
