When importing data from CSV or another source, you may need to check every record whether it exists in the DB already, and then update that record, otherwise create a new one. There are multiple ways to perform it.
Imagine we're importing a CSV with 1000+ records of accounts from CSV.
The original array $accountsArrayFromCSV - column 0 is the account number, column 1 is the account balance:
array ( 0 => array ( 0 => '610768', 1 => '630', ), 1 => array ( 0 => '773179', 1 => '403', ), 2 => array ( 0 => '346113', 1 => '512', ), // ...);For that import, you may see this code:
foreach ($accountsArrayFromCSV as $row) { $account = Account::where('number', $row[0])->first(); if ($account) { $account->update(['balance' => $row[1]]); } else { Account::create([ 'number' => $row[0], 'balance' => $row[1] ]); }}This code will work, as it does exactly what is needed: look for the records and then update/create them.
But there are two problems:
If we take a look at what Laravel Debugbar shows, it's this:
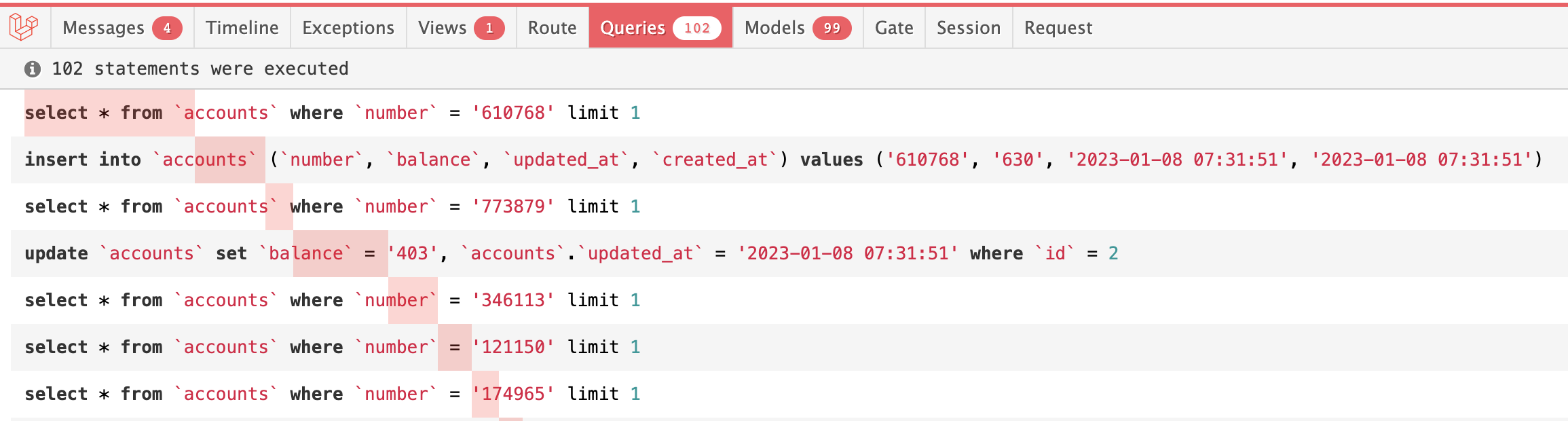
In this case, I already have 100 accounts in the DB, and intentionally changed 2 records in the imported CSV: 1 with the new account number and 1 with the updated balance.
As you can see, it's launching select for every record, and insert/update for the new/updated records.
So, we have at least 100 DB queries or as many queries as the number of rows in the CSV source. Plus insert/update operations, so potentially up to 200 queries.
Here are the potential solutions.
The same code can be accomplished with the Eloquent function updateOrCreate().
foreach ($accountsArrayFromCSV as $row) { Account::updateOrCreate( ['number' => $row[0]], // key to search by ['balance' => $row[1]] // update the value );}This is a simplified example with two fields. The first array parameter is the condition for the where() statement to look up the record, and the second array parameter is the set of values to be merged with that key parameter for update/create.
However, this optimization is only for readability. The code is shorter, but it doesn't improve the performance. It launches the same amount of DB queries as the original code: 2 queries per account record.
Since Laravel 8, there is a possibility to combine those queries into the upsert() method that would build ONE database query from the records. Then we don't need that foreach loop at all.
For that, we need to transform the original CSV to contain the keys corresponding to DB columns:
array ( 0 => array ( 'number' => '610768', 'balance' => '630', ), 1 => array ( 'number' => '773179', 'balance' => '403', ), 2 => array ( 'number' => '346113', 'balance' => '512', ), // ...);Then, the Eloquent syntax is this:
Account::upsert($accountsArrayFromCSV, ['number'], ['balance']);The second argument lists the column(s) that uniquely identify records within the associated table. The method's third and final argument is an array of columns that should be updated if a matching record already exists in the database.
The result DB query is this:
insert into `accounts` (`balance`, `created_at`, `number`, `updated_at`) values ('630', '2023-01-08 07:52:23', '610768', '2023-01-08 07:52:23'), ('403', '2023-01-08 07:52:23', '773179', '2023-01-08 07:52:23'), // ... ('828', '2023-01-08 07:52:23', '935461', '2023-01-08 07:52:23') on duplicate key update `balance` = values(`balance`), `updated_at` = values(`updated_at`);Yes, it's ONE query. Yes, it's much faster. BUT.
The problem is that it may be often incorrect. See that on duplicate key part?
The downside of this upsert() method is its limitation, quote from the docs:
All databases except SQL Server require the columns in the second argument of the upsert method to have a "primary" or "unique" index. In addition, the MySQL database driver ignores the second argument of the upsert method and always uses the "primary" and "unique" indexes of the table to detect existing records.
So, we can use this only if our DB column number is unique on the database level, and for MySQL, it would always compare with the primary "id" field. Which is not always possible or convenient, in such import scenarios.
But if we meet that condition, then it's great: we optimized our performance by a huge amount.
In case we can't use the upsert() because our DB structure doesn't meet the key condition, we can optimize the foreach loop to check the records from memory and not call the DB every time.
To do that, we download ALL relevant records from the DB once, store them in a Collection or array, and then check with that Collection every time.
$accounts = Account::pluck('balance', 'number');// This becomes the array of key-value pairs, number => balance foreach ($accountsArrayFromCSV as $row) { if (isset($accounts[$row[0]])) { if ($accounts[$row[0]] != $row[1]) { // We launch update only if the value changed Account::where('number', $row[0])->update(['balance' => $row[1]]); } } else { Account::create([ 'number' => $row[0], 'balance' => $row[1] ]); }}As you can see, we're launching only ONE query to get the data, and then keep comparing the CSV values with the $accounts, instead of the database.
In this simple case of only two fields, one becomes the key and another becomes the value, so we can use the pluck() method.
In more complicated cases with more than one field for the value, you could use something like ->keyBy() on Collection.
Let's say, we have balance and verified_at columns.
$accounts = Account::all()->keyBy('number');foreach ($accountsArrayFromCSV as $row) { if (isset($accounts[$row[0]])) { $account = $accounts[$row[0]]; if ($account->balance != $row[1] || $account->verified_at != $row[1]) { Account::where('number', $row[0])->update([ 'balance' => $row[1], 'verified_at' => $row[2], ]); } } else { Account::create([ 'number' => $row[0], 'balance' => $row[1], 'verified_at' => $row[2], ]); }}As a result, we will have much fewer queries.
If the data didn't change compared to the CSV, we would have only ONE query to the database: to get all the accounts.
If some data has changed, we would launch one query for each created/updated record.
Let's take a look at the create() part of our loop:
foreach ($accountsArrayFromCSV as $row) { if (record_exists()) { // ... } else { Account::create([ 'number' => $row[0], 'balance' => $row[1] ]); }}If we have 100 new records, we will still launch 100 insert queries to the DB.
Can we somehow combine them into one big insert?
Yes, by switching from the Eloquent create() method to the Query Builder insert() method which accepts array of records.
So, instead of creating the records on the spot, we will just populate the array, to be inserted later, after the loop.
$accounts = Account::pluck('balance', 'number');$newAccounts = [];foreach ($accountsArrayFromCSV as $row) { if (isset($accounts[$row[0]])) { // ... update } else { $newAccounts[] = [ 'number' => $row[0], 'balance' => $row[1] ]; }}if (count($newAccounts) > 0) { Account::insert($newAccounts);}As a result, we will have only TWO queries: one to get all the accounts, and one to insert all new accounts.
insert into `accounts` (`balance`, `number`) values ('630', '610068'), ('403', '773279'), ('837', '121050');Looks like the greatest and the quickest solution, right? But not so fast.
If you use insert() on the model, keep in mind its limitations: insert() is a Query Builder and not an Eloquent method. So, it wouldn't trigger any of the Eloquent features:
In other words, insert() is literally a query to the database, that's it. Almost like a raw SQL query.
Of course, you can pre-fill all the necessary values yourself, like:
$newAccounts[] = [ 'number' => $row[0], 'balance' => $row[1], 'created_at' => now()->toDateTimeString(), 'updated_at' => now()->toDateTimeString(),];But if you have more complex "background" Eloquent logic on creating a new record, possibly the insert() method won't be a good fit for you.
Question: what do you think would happen if we try to pass 100,000 records to that Account::insert() method?
Yes, it will likely fail, on the database level. There is a limit to how much data you can pass to one SQL statement, so you may encounter an error something like "Prepared statement contains too many placeholders".
To work around that, we would need to cut the full array into slices called "chunks", and execute a bit more SQL queries than just one.
This is the code:
if (count($newAccounts) > 0) { foreach (array_chunk($newAccounts, 1000) as $chunk) { Account::insert($chunk); }}You can play around and experiment with that 1000 parameter value, calculating the overall speed of the import, depending on your situation and the imported data, every case may be individual.
Another thing to consider, which I haven't mentioned in the article, is the possibility of arrays being too large to be stored in the RAM as a PHP variable. That is worth a separate tutorial, but essentially, you need to get creative to avoid temporary array variables and evaluate the performance of every operation separately.
I've also seen other optimization methods mentioned online, so if you have a HUGE amount of data, and the tips above are not sufficient enough for you, you may read about:
.png-674b51a81d08b.jpg)