.png-674b519a8f3bb.jpg)
I recently worked with an Eloquent query with the where status = 'new' filter by ENUM value, which felt quite slow. I experimented with changing it to status_id instead as a big/tiny integer with a foreign key. Was it faster? Let's find out together.
At the end of this tutorial, you'll find the link to the GitHub repository, so you can play around and experiment, too.
The situation comes from the official Filament demo, where I seeded 1M orders and had a menu badge for counting the new orders:
![]()
That executed this SQL query under the hood:
select count(*) as aggregate from `shop_orders` where `status` = 'new' and `shop_orders`.`deleted_at` is nullThe column status was created as ENUM on the DB level:
Schema::create('shop_orders', function (Blueprint $table) { $table->id(); // ... other fields $table->enum('status', [ 'new', 'processing', 'shipped', 'delivered', 'cancelled' ])->default('new'); // ... other fields $table->timestamps(); $table->softDeletes();});According to the Laravel Debugbar, the average execution time was around 150 ms.

Not very bad, but my initial reaction was that it could be faster to search where status_id = 1 or something.
So, here's my experiment.
First, a few Artisan commands to create separate models/migrations:
php artisan make:model Status -mphp artisan make:model TinyStatus -mAnd then, structure with the initial data seeded right away in migrations:
use App\Models\Status; // ... return new class extends Migration{ public function up(): void { Schema::create('statuses', function (Blueprint $table) { $table->id(); $table->string('name'); $table->timestamps(); }); Status::create(['name' => 'new']); Status::create(['name' => 'processing']); Status::create(['name' => 'shipped']); Status::create(['name' => 'delivered']); Status::create(['name' => 'cancelled']); } };Separately, the same for Tiny Statuses:
use App\Models\TinyStatus; // ... return new class extends Migration{ public function up(): void { Schema::create('tiny_statuses', function (Blueprint $table) { $table->tinyIncrements('id'); $table->string('name'); $table->timestamps(); }); TinyStatus::create(['name' => 'new']); TinyStatus::create(['name' => 'processing']); TinyStatus::create(['name' => 'shipped']); TinyStatus::create(['name' => 'delivered']); TinyStatus::create(['name' => 'cancelled']); }};By the way, did you know about the ->tinyIncrements() method? It creates a TINYINT column as an auto-incremented primary key instead of a default BIGINT generated by $table->id().
Notice: I also added the name column in both Models into a $fillable array.
Now, let's create two columns in the shop_orders table: one foreign key to the statuses table and another one on the tiny_statuses table:
php artisan make:migration add_columns_to_shop_orders_tableHere's the Migration code:
public function up(): void{ Schema::table('shop_orders', function (Blueprint $table) { $table->foreignId('status_id')->default(1)->constrained(); $table->unsignedTinyInteger('tiny_status_id')->default(1); $table->foreign('tiny_status_id')->references('id')->on('tiny_statuses'); }); $sqlStatus = "UPDATE shop_orders set status_id = case when status='new' then 1 when status='processing' then 2 when status='shipped' then 3 when status='delivered' then 4 when status='cancelled' then 5 else 5 end"; \Illuminate\Support\Facades\DB::statement($sqlStatus); $sqlTinyStatus = 'UPDATE shop_orders set tiny_status_id=status_id'; \Illuminate\Support\Facades\DB::statement($sqlTinyStatus);}As you can see, we immediately set the values of the new columns with SQL statements.
Side note: it may not be ideal to execute SQL and Eloquent statements directly in migrations, but I'm doing it simply to avoid extra paragraphs of text about seeding and explaining how to launch it.
As a result, we have this in the database:
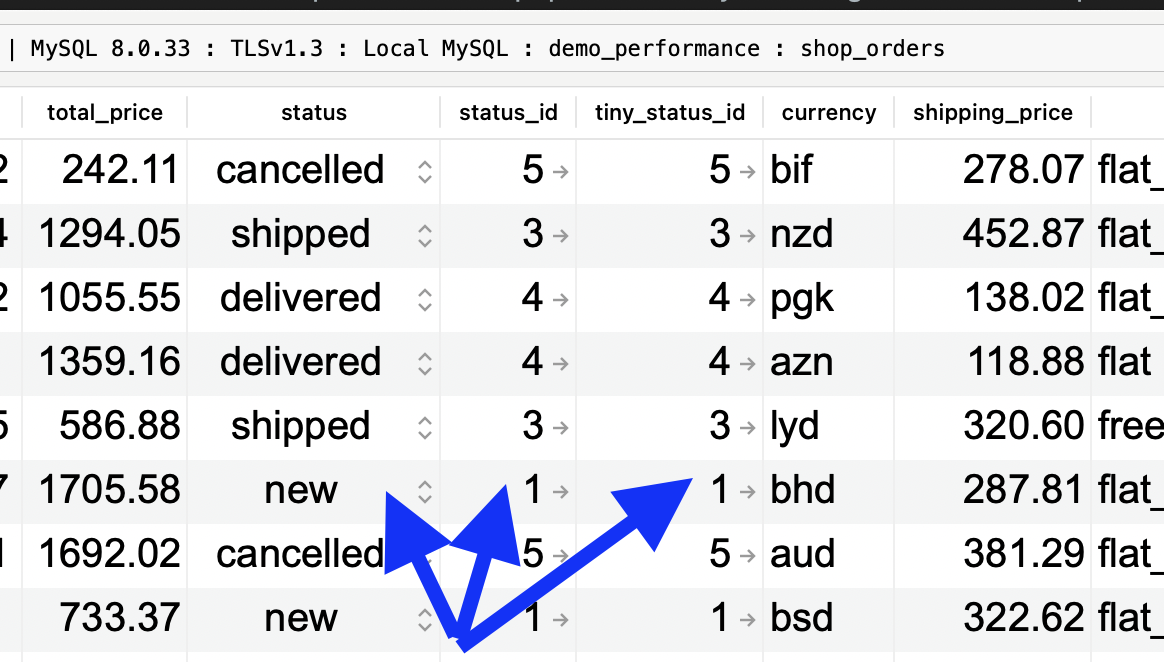
We're ready to use those columns and measure the improvement results.
->where() Condition: Is It Faster?Now, the place where I had this condition is in the OrderResource of Filament.
app/Filament/Resources/OrderResource.php
class OrderResource extends Resource{ // ... public static function getNavigationBadge(): ?string { /** @var class-string<Model> $modelClass */ $modelClass = static::$model; return (string) $modelClass::where('status', 'new')->count(); } // ... }Let's change it to use status_id.
return (string) $modelClass::where('status', 'new')->count(); return (string) $modelClass::where('status_id', 1)->count(); Refreshing the page to see if it is faster than the previous 150ms...

Wait, WHAT?! 327ms? So, it's 2x slower? Relaunching the page just to double-check...

It's a bit better with 281ms, but still slower. So, it wasn't a coincidence :(
Ok, maybe it's because of the BIGINT? Let's try the tiny_status_id.
return (string) $modelClass::where('status_id', 1)->count(); return (string) $modelClass::where('tiny_status_id', 1)->count(); 
That's even weirder. So, 289ms means no improvement with having a smaller field? What the...?
Just to make sure, I ran a test with Benchmark Laravel class and 10 iterations:
use App\Models\Shop\Order;use Illuminate\Support\Facades\Route;use Illuminate\Support\Benchmark; Route::get('benchmark', function() { Benchmark::dd([ "Enum" => fn() => Order::where("status", "new")->count(), "Bigint" => fn() => Order::where("status_id", 1)->count(), "Tinyint" => fn() => Order::where("tiny_status_id", 1)->count() ], 10);});Results may be unexpected, but pretty clear:
array:3 [▼ // vendor/laravel/framework/src/Illuminate/Support/Benchmark.php:67 "Enum" => "181.001ms" "Bigint" => "270.180ms" "Tinyint" => "258.069ms"]Mmmkay... but... why enums are faster?
The first thought on DB performance is about indexes, right? Do we have/use them?
By default, Laravel adds an index to the ->foreign() or ->foreignId() in Migrations, so our table has these indexes:

The first two rows are exactly what we need.
There's no index on ENUM, but I guess we don't really need it?
To check if they are actually used, I've run the EXPLAIN sentence on all three SQL queries:
EXPLAINselect count(*) as aggregate from `shop_orders` where `status` = 'new' and `shop_orders`.`deleted_at` is nullAnd identical statements for status_id and tiny_status_id.
Then, to translate it into a more "human-friendly language", I've put the result into a great free tool MySQL Explain by Tobias Petry.
Here are the results in two tables.
Simplified:

Annotated:

So, what do we see here?
status_id vs 1 for tiny_status_id: this is the reason why the tiny_status_id is a bit fasterIt seems that MySQL joins the statuses and tiny_statuses tables when we perform a lookup using the foreign key table.
So that's what slows it down, maybe?
To experiment, I've created another column of status_number TINYINT with an index but without a foreign key. Let's test that one.
New migration:
Schema::table('shop_orders', function (Blueprint $table) { $table->unsignedTinyInteger('status_number')->default(1)->index();}); $sqlStatusNumber = 'UPDATE shop_orders set status_number=tiny_status_id';\Illuminate\Support\Facades\DB::statement($sqlStatusNumber);Now, what would we see if we perform this:
return (string) $modelClass::where('tiny_status_id', 1)->count(); return (string) $modelClass::where('status_number', 1)->count(); 
Nope, not faster :(
Benchmark results?
Code:
Benchmark::dd([ "Enum" => fn() => Order::where("status", "new")->count(), "Bigint" => fn() => Order::where("status_id", 1)->count(), "Tinyint" => fn() => Order::where("tiny_status_id", 1)->count(), "No FK" => fn() => Order::where("status_number", 1)->count(),], iterations: 10);Results:
array:4 [▼ // vendor/laravel/framework/src/Illuminate/Support/Benchmark.php:67 "Enum" => "179.509ms" "Bigint" => "261.451ms" "Tinyint" => "261.023ms" "No FK" => "260.080ms"]Confirmed.
Kind of a side-note but very important. The numbers above are from testing on my local Macbook Pro with an M3 processor.
Most real projects are deployed on much less powerful servers.
So, out of curiosity, I decided to deploy the same code on the cheapest Digital Ocean droplet for $6.
The Debugbar shows that the main query we're talking about using ENUM is loading in 500-600ms.

Reminder: the local query runs in 150ms. So, 4x difference?
Tried the Benchmark:
array:4 [▼ // vendor/laravel/framework/src/Illuminate/Support/Benchmark.php:67 "Enum" => "1,079.821ms" "Bigint" => "4,460.764ms" "Tinyint" => "4,484.240ms" "No FK" => "4,594.815ms"]Wow. Even slower than 4x.
So the ENUM is ~8x slower, but integer fields are slower by whooping ~17x! Yes, that's not 17%, that's 1700%.
And that's with only me testing, no other users accessing the page simultaneously.
That's why what seems like an insignificant 50-100ms difference locally may become 0.5-1s on the server.
Not to mention, you may just physically run out of RAM on your VPS while executing queries. I had to lower benchmark iterations from 10 to 2 to avoid a 504 gateway timeout.
deleted_at?Another idea hit me: all those queries include SoftDeletes and the where deleted_at is null condition.
That condition exists in all queries, so it seems that we're comparing "apples to apples" here. But what if we try to disable SoftDeletes and see the benchmark?
app/Models/Shop/Order.php:
class Order extends Model{ use HasFactory; use SoftDeletes; If we launch the tiny_status_id query first... Reminder: it was 261ms.

Now it's 23ms, much faster!
Now, re-running the benchmark for all four types of queries...
array:4 [▼ // vendor/laravel/framework/src/Illuminate/Support/Benchmark.php:67 "Enum" => "157.251ms" "Bigint" => "17.130ms" "Tinyint" => "16.021ms" "No FK" => "16.416ms"]Wait, WHAT?! Now Enum is 10x slower?
Or, in other words, the time of ENUM didn't change from 150ms, but other options dropped drastically from 280ms to 16ms?
So, it seems that deleted_at is causing the slowness of those new int/tinyint fields.
But we can't just remove it. It's a part of our application now. So what do we do?
deleted_atEarlier, I said that when doing foreignId(), Laravel automatically creates an index on the foreign key.
But what we actually need is the index on TWO columns:
status and deleted_at
status_id and deleted_at
tiny_status_id and deleted_at
status_number and deleted_at
It's called composite or multi-column index.
Let's run this command:
php artisan make:migration add_composite_indexes_to_shop_orders_tableThis is the migration code:
Schema::table('shop_orders', function (Blueprint $table) { $table->index(['status', 'deleted_at']); $table->index(['status_id', 'deleted_at']); $table->index(['tiny_status_id', 'deleted_at']); $table->index(['status_number', 'deleted_at']);});Notice: here are the docs about creating indexes in Laravel.
Of course, we return the use SoftDeletes; to the Order.php model.
Let's launch the ENUM query now.

There we go! From 150ms to 31ms: 5x faster!
Now, what about Benchmark?
array:4 [▼ // vendor/laravel/framework/src/Illuminate/Support/Benchmark.php:67 "Enum" => "25.079ms" "Bigint" => "20.312ms" "Tinyint" => "20.073ms" "No FK" => "20.109ms"]Now this is where we're getting something useful and logical!
With the same composite index, ENUM is actually a little bit slower than the INT fields.
Interestingly, TINYINT doesn't offer much benefit over BIGINT in terms of query; it just takes less space on disk.
Speaking of space...
Great. We optimized the query, but adding the index added quite a few MB to our database. Take a look.
If we run this SQL query:
SELECT index_name,ROUND(stat_value * @@innodb_page_size / 1024 / 1024, 2) size_in_mbFROM mysql.innodb_index_statsWHERE stat_name = 'size' AND index_name != 'PRIMARY' and database_name = 'demo_performance' and table_name = 'shop_orders'ORDER BY size_in_mb DESC;We see how much space is taken by each index:

So, each index adds 17-27MB to our DB, for 1M records.
Here's what the general table size looks like in my TablePlus:

As you can see, indexes take more space now than the data itself.
Also, in theory, you slow the INSERT operations with each index, but you wouldn't really feel it in most cases because most apps are more SELECT-heavy, so more people select data than add new data.
So, don't overpush with indexing all possible columns.
Final note: if those 20ms are still too slow for you (on the live server, it's probably 100ms), you can try caching Eloquent results.
We have a quick tutorial on caching, but the basics for this case would be this:
app/Filament/Resources/Shop/OrderResource.php:
use Illuminate\Support\Facades\Cache; // ... public static function getNavigationBadge(): ?string{ /** @var class-string<Model> $modelClass */ $modelClass = static::$model; return (string) $modelClass::where('status', 'new')->count(); return (string) Cache::remember('new_orders_count', 60 * 60, function () use ($modelClass) { return $modelClass::where('status', 'new')->count(); }); }Notice: that 60 * 60 number means caching for 1 hour: 60 seconds x 60 minutes. The parameter itself excepts seconds, but it's easier to read and understand 60 * 60 than 3600.
Just remember to clear that cache when the new Order is added to the DB or (soft-)deleted. You can do that with Observer class, for example:
php artisan make:observer ShopOrderObserver --model=Shop/OrderHere's the code:
app/Observers/ShopOrderObserver.php:
namespace App\Observers; use App\Models\Shop\Order;use Illuminate\Support\Facades\Cache; class ShopOrderObserver{ public function created(Order $order): void { Cache::forget('new_orders_count'); } public function deleted(Order $order): void { Cache::forget('new_orders_count'); } public function restored(Order $order): void { Cache::forget('new_orders_count'); } public function forceDeleted(Order $order): void { Cache::forget('new_orders_count'); }}Then, register this Observer in the Model:
app/Models/Shop/Order.php:
use App\Observers\ShopOrderObserver;use Illuminate\Database\Eloquent\Attributes\ObservedBy; // ... #[ObservedBy(ShopOrderObserver::class)]class Order extends Model{ // ...Now, whenever you add a new Order, the cache will be cleared, and the data will be taken from the DB next time and re-cached again.
It was a pretty wild ride to benchmark everything and then write (and re-write) this article. But, in the end, here are the takeaways:
tinyIncrements().SoftDeletes, put them into composite indexes with other indexed columns.Anything you would add?
Finally, as I promised, here's the GitHub repository for this experiment. Just don't forget to skip migrations and run the SQL file linked in the Readme instead to have 1M orders seeded.
.png-674b526369b42.jpg)
.png-674b523429100.jpg)

;-(19).png-674b51c1051a5.jpg)
.png-674b51bdce9df.jpg)
