.png-674b51a4d5cae.jpg)
Looking at Laravel job descriptions, you will find Redis quite often. This tutorial will cover the basics of using it with Laravel and how to use it in your projects.
Look at these job description examples:

Generally, in Laravel, Redis is used for two purposes:
In this tutorial, we will cover both.
As a "teaser", here's what the Laravel queue looks like when using Redis.
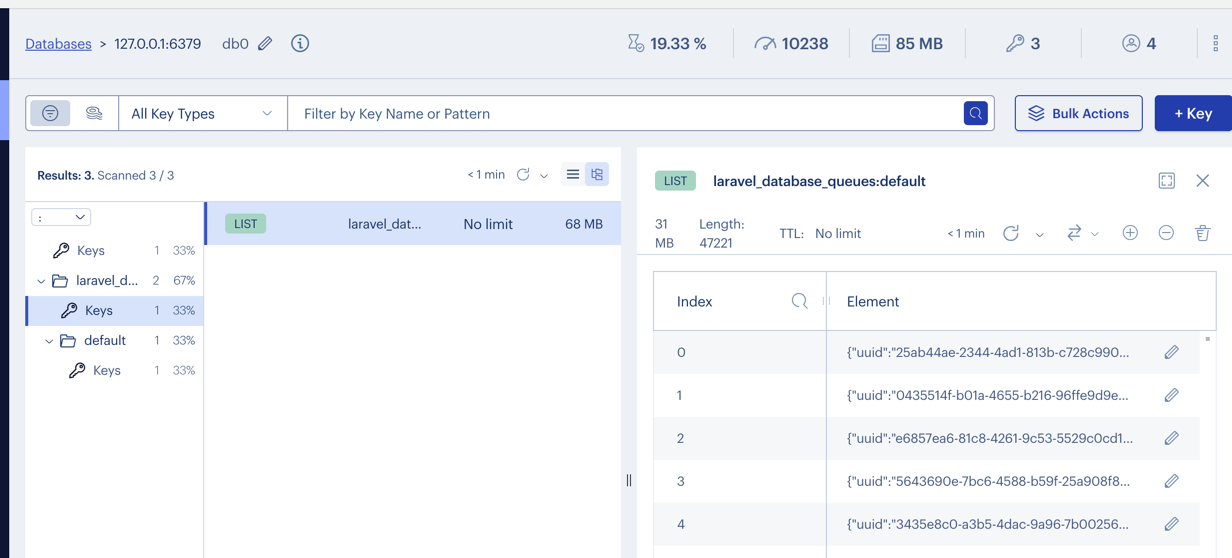
This tutorial will generally consist of three main parts:
Here's what you will see inside this long tutorial.
A long journey ahead, huh? Let's dive in, then!
In short, we can treat Redis as a "database" stored in memory. It is not a database like MySQL or Postgres but a key-value store that can be used to store data in memory. This means that we can store keys like this:
KEY VALUE # For example:widget:total 100 # This will store the value 100 in the key widget:totalThis will allow us to store data in memory (system RAM) and access it very quickly. And we mean VERY quickly. Redis is so fast that it can handle millions of requests per second. This makes it an excellent tool for caching data used often or storing data that needs to be accessed quickly. For example, it's a great place to store complex data (like report totals) that needs to be accessed often but takes a long time to calculate.
Of course, Redis is not limited by this. It can be used to store any data that you want. It can be used as a cache, as a database, as a message broker, as a queue, and much more. It is a versatile tool that can be used in many ways as it supports many data types. You can even write your own commands for it using Lua if you want to.
That said, we understand that it is a lot to process. Let's start with the basics and see how to use Redis in our Laravel applications.
Running Redis on your local machine might seem complex, but there is excellent documentation that covers all platforms.
You only need to focus on how you will launch it. If you have a supervisor set up - fantastic, but if not - you can run it with this command:
redis-serverOnce done, you can use your Redis instance with the redis-cli command.
We recommend you install a tool called RedisInsight as this will allow you to monitor your Redis instance and see what is going on:
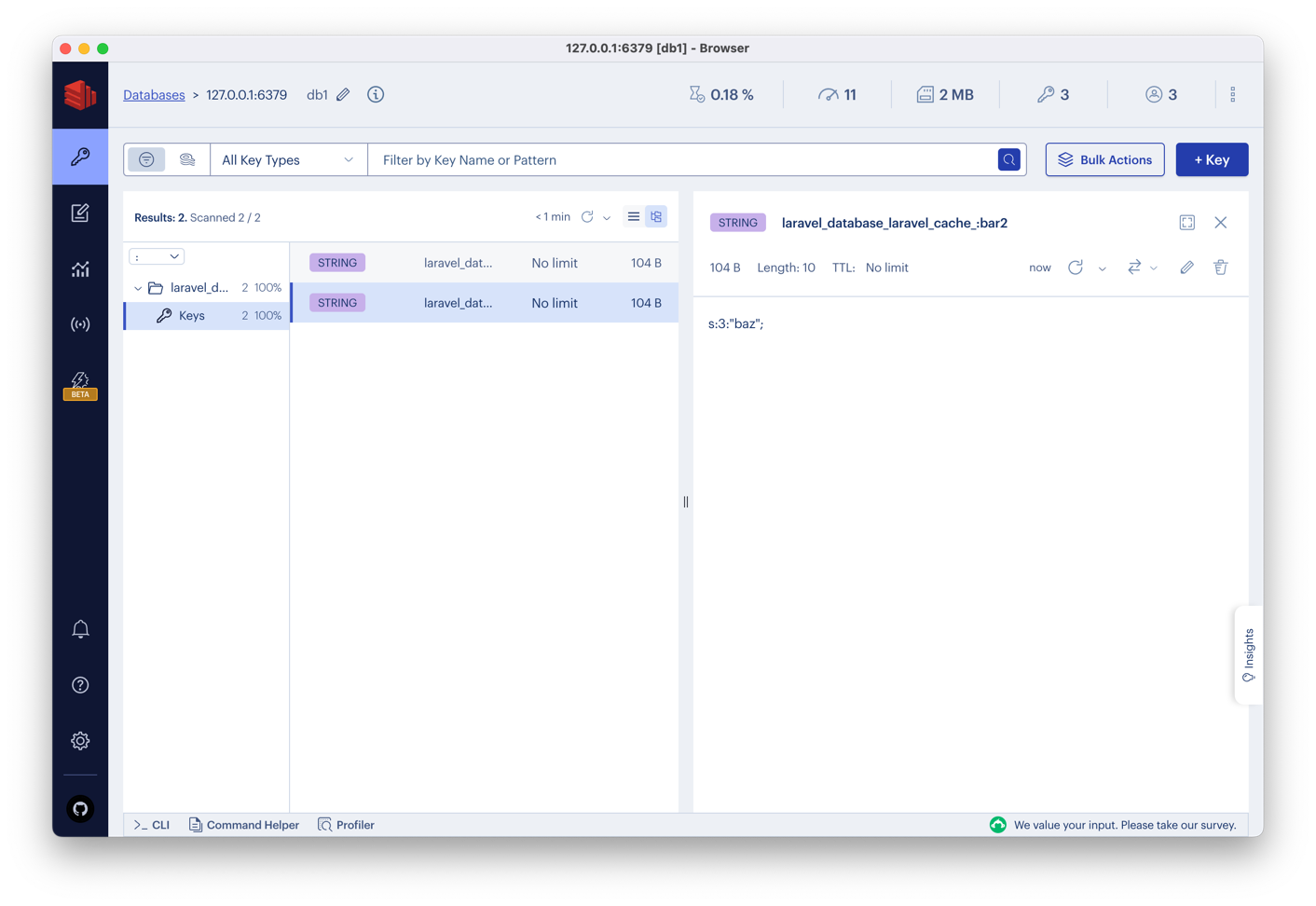
It is an excellent tool as you can run the profiler and see what commands are being executed and how long they take:

You can also switch multiple databases (Laravel uses database 0 for all Redis things and database 1 for cache by default). To do this, you change this number:
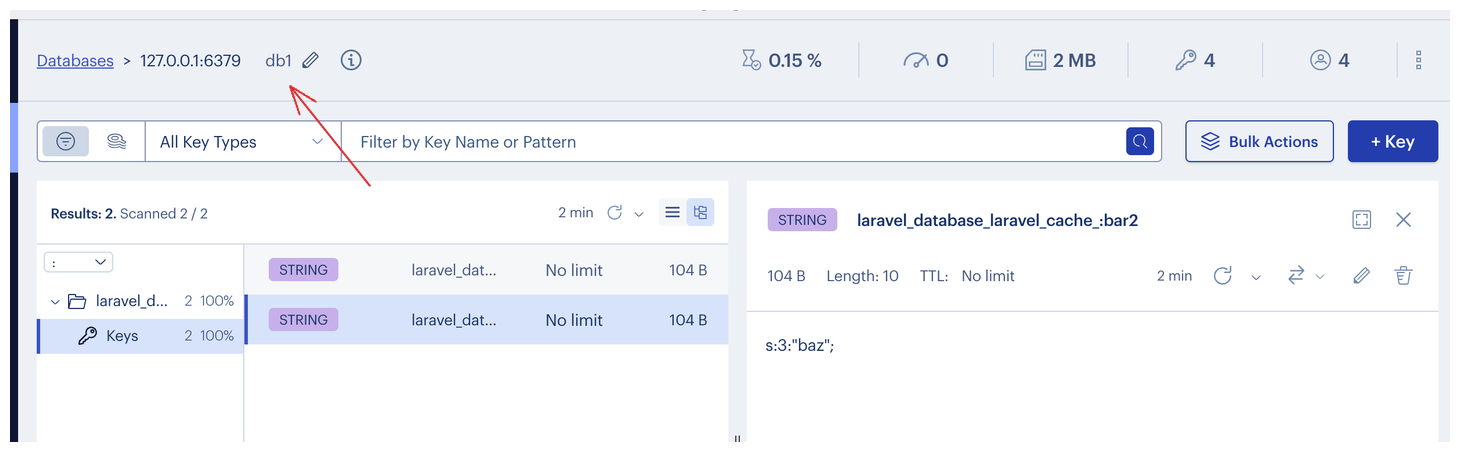
Once you click it, you can enter 1 or 0 to switch between databases. Of course, you can create more database instances (there are 16 of them by default) if you want to, but that is something other than what we will cover in this tutorial.
Before diving into Laravel implementation examples, we need to understand our options for reading and writing data to Redis. There are two ways to do this:
This tutorial will cover both ways, but your chosen option will depend on your needs. You will see us using two styles of code:
// Cache Facadeuse Illuminate\Support\Facades\Cache; Cache::driver('redis')// or if your .env file has CACHE_DRIVER=redisCache:: // Redis Facadeuse Illuminate\Support\Facades\Redis; Redis::command()To start with Redis in Laravel, you must install the predis/predis package, as it is not included by default. Without it, you will get Class 'Redis' not found error:

To install it, run this command:
composer require predis/predisOnce that is done, you can use the Illuminate\Support\Facades\Redis facade to interact with Redis or configure your cache driver to use Redis by setting CACHE_DRIVER=redis in your .env file.
We will show a few examples of Laravel projects. The first one will be about caching number values from the array, which means you can cache any PHP variable(s) into Redis.
To show you how to use Redis, we have created a simple Laravel project with a Product model. We will seed big amount of products and compare the page loading time with/without caching.
Migration
Schema::create('products', function (Blueprint $table) { $table->id(); $table->string('name'); // Testing purpose $table->double('price'); $table->integer('quantity'); $table->integer('sold_units'); $table->timestamps();});Model
use Illuminate\Database\Eloquent\Factories\HasFactory;use Illuminate\Database\Eloquent\Model; class Product extends Model{ use HasFactory; protected $fillable = [ 'name', 'price', 'quantity', 'sold_units', ];}Factory
class ProductFactory extends Factory{ protected $model = Product::class; public function definition(): array { return [ 'name' => $this->faker->name(), 'price' => $this->faker->randomFloat(2, 1, 1000), 'quantity' => random_int(1, 100_000), 'sold_units' => random_int(1, 1_000_000), ]; }}And last, we seed the database with 300 000 products:
$parts = 30; for ($i = 1; $i <= $parts; $i++) { Product::factory() ->count(10_000) ->create();}Next, we attempt to calculate some totals for our products:
Controller
use App\Models\Product; class DashboardController extends Controller{ public function __invoke() { return view('dashboard', [ ...$this->calculateTotalValues(), ]); } private function calculateTotalValues(): array { $array = [ 'totalValue' => 0, 'totalSoldValue' => 0, 'totalCombinedValue' => 0, ]; $products = Product::all(); foreach ($products as $product) { $array['totalValue'] += $product->price * $product->quantity; $array['totalSoldValue'] += $product->price * $product->sold_units; $array['totalCombinedValue'] += $product->price * ($product->quantity + $product->sold_units); } return $array; }}And display them in the view:
View
<x-app-layout> <x-slot name="header"> <h2 class="font-semibold text-xl text-gray-800 leading-tight"> {{ __('Dashboard') }} </h2> </x-slot> <div class="py-12"> <div class="max-w-7xl mx-auto sm:px-6 lg:px-8"> <div class="bg-white overflow-hidden shadow-sm sm:rounded-lg"> <div class="p-6 text-gray-900 flex justify-evenly"> <div class=""> <h1>Total Product Value</h1> <span>{{ $totalValue }}</span> </div> <div class=""> <h1>Total Sold Value</h1> <span>{{ $totalSoldValue }}</span> </div> <div class=""> <h1>Total Combined Value</h1> <span>{{ $totalCombinedValue }}</span> </div> </div> </div> </div> </div></x-app-layout>That's it. Loading this page after the database is seeded takes about 3 seconds, which means we can do better:

Note: Loading all models as we did is not recommended, and this should use database queries as they are faster, but for this tutorial, we intentionally wanted to make it slow.
In our example project, we want to cache the end result of our calculations. To do this, we need to add a few lines:
Controller
use Cache; // ... private function calculateTotalValues(): array{ if (Cache::driver('redis')->has('totalValuesCached')) { return [ 'totalValue' => Cache::driver('redis')->get('totalValue'), 'totalSoldValue' => Cache::driver('redis')->get('totalSoldValue'), 'totalCombinedValue' => Cache::driver('redis')->get('totalCombinedValue'), ]; } $array = [ 'totalValue' => 0, 'totalSoldValue' => 0, 'totalCombinedValue' => 0, ]; $products = Product::all(); foreach ($products as $product) { $array['totalValue'] += $product->price * $product->quantity; $array['totalSoldValue'] += $product->price * $product->sold_units; $array['totalCombinedValue'] += $product->price * ($product->quantity + $product->sold_units); } Cache::driver('redis')->put('totalValue', $array['totalValue']); Cache::driver('redis')->put('totalSoldValue', $array['totalSoldValue']); Cache::driver('redis')->put('totalCombinedValue', $array['totalCombinedValue']); Cache::driver('redis')->put('totalValuesCached', true); return $array;}Now, when we load the page for the first time - it will take about 3 seconds, but when we reload it - it will be much faster:

This is because we stored our results in Redis:

And we are not doing any calculations when we reload the page. We get the data from Redis and display it. This is much faster than doing the math every time.
So far, we cached the data forever. And while it is a valid approach, there will only be updates if we clear the cache manually. To fix this, we can add expiration to our cache:
Controller
Cache::driver('redis')->put('totalValue', $array['totalValue']);Cache::driver('redis')->put('totalSoldValue', $array['totalSoldValue']);Cache::driver('redis')->put('totalCombinedValue', $array['totalCombinedValue']);Cache::driver('redis')->put('totalValuesCached', true); Cache::driver('redis')->put('totalValue', $array['totalValue'], 600);Cache::driver('redis')->put('totalSoldValue', $array['totalSoldValue'], 600);Cache::driver('redis')->put('totalCombinedValue', $array['totalCombinedValue'], 600);Cache::driver('redis')->put('totalValuesCached', true, 599);We added a third parameter to our ->put() method: the number of seconds the cache will be valid for. In our case, we set it to 10 minutes (600 seconds). This means that after 10 minutes, the cache will expire, and we will need to recalculate the values. We can also see this in RedisInsight:

This is a great way to cache data that can be updated periodically.
For example, if our dashboard shows the total value of products sold with a 24-hour delay - we can cache the result for 24 hours and then use a scheduled job to recalculate the values every 24 hours. This will speed up our dashboard for the end user.
In our previous examples, we cached the results. But there is another way to use Cache here. We can cache the models themselves:
Controller
$products = Cache::driver('redis')->remember('products_query', 600, function () { return Product::query()->limit(10_000)->get();});Note: We only took 10,000 products as trying to cache 300 000 products will take a lot of memory and usually causes an Allowed memory size of XXXXX bytes exhausted (tried to allocate XXXX bytes) error. Be careful with this.
Now, loading our page, we can see that we queried the database and loaded 10,000 Models:

But after reloading the page, we can see that we did not query the database and instead loaded the models from Redis:

And if we look at RedisInsight, we can see that we cached the models:

Of course, this is a drastic simplification, but we can use Redis to cache various data types. While we just used a simple string type for our cache, redis supports many more types, so let's look at them in the next section.
While we just looked at simple caching, Redis is used for more than that. In Laravel, you often find Redis responsible for your Queue. Here's what that looks like:
.env
QUEUE_CONNECTION=redisNow, when we push a job to the Queue, it will be stored in Redis:
dispatch(new ProcessProductJob($product));And we can see it in RedisInsight:
This has used the list type to store the data. And we can see that the data is stored in JSON format:

Now, Laravel queue workers can load and process the job from Redis the fastest way possible.
Naming conventions are important. They allow us to keep our code clean and easy to understand. And Redis is no different. It has a few naming rules that we should follow:
products:total instead of productstotal.products:total instead of PRODUCTS:TOTAL.products:total_value instead of products:total-value.While this is not a requirement, we wanted to mention it as it is a good practice to follow. It will also make it easier to query the data and set standards for your team.
We looked at simple Redis usage with strings and queue lists, but Redis supports various data types. Let's take a look at them:
Strings are the most straightforward data type to understand. They are just a key-value pair. For example, we can store a string like this:
Cache::driver('redis')->put('KEY', 'VALUE');This will store our value into the key on Redis, and we can retrieve it like this:
Cache::driver('redis')->get('KEY');That is it. You can put any string (yes, even JSON, but for that, you should look into lists/sets) into Redis like this. Just remember that it has a limit of 512MB (which is a lot!).
Next, we have lists that are similar to arrays. We can store multiple values in a list and then retrieve them. For example, we can store a list like this:
Important: While Laravel has Cache helper, we use the Redis facade here because it is more powerful and allows us to use it directly. This will enable us to use all Redis commands (more on that later).
$products = Product::query()->limit(100)->get(); foreach ($products as $product) { Redis::command('LPUSH', ['products', $product]);}This will store our products in a list called products:

And we can retrieve them like this:
// Redis::command('LRANGE', ['products', FROM INDEX, TO INDEX]);$products = Redis::command('LRANGE', ['products', 0, 10]);This will return the first 10 products from our list:

But as you can see, when we stored our products, we pushed new records to the top of the list and not the bottom. This is because we used the LPUSH command, which pushes new records to the top of the list. If we want to push new records to the bottom of the list, we can use the RPUSH command:
$products = Product::query()->limit(100)->get(); foreach ($products as $product) { Redis::command('RPUSH', ['products', $product]);}This will push new records to the bottom of the list:

And we can retrieve them like this:
$products = Redis::command('LRANGE', ['products', 0, 10]);This will return the first 10 products from our list:

Lists are great for storing data that needs to be in order but can be repeated (does not have to be unique). And you can retrieve the details one by one or in bulk. For example, we can retrieve the first 10 products and remove them from the list like this:
$products = Redis::command('LPOP', ['products', 10]);This will return the first 10 products from our list and remove them from the list (so we can't retrieve them again):

It can be helpful if you want to process the data in batches. For example, if you have a queue of 1000 products that need to be processed, you can retrieve and process 100 products at a time. This will allow you to process the data in batches and not all at once while still keeping the order of the data.
Next on our list are sets. They are similar to lists but have one significant difference. They do not allow duplicates and have no index. To store a set, we can use the SADD command:
$products = Product::query()->limit(100)->get(); foreach ($products as $product) { Redis::command('SADD', ['products', $product->id]);}This will store our products in a set called products:

And we can retrieve them like this:
$products = Redis::command('SMEMBERS', ['products']);This will return all products from our set:

As you can see, we can only retrieve the whole set and not individual records. This is because sets do not have indexes. They are just a collection of unique values. And if we try to add a duplicate value to a set, it will be ignored.
To check if a value exists in a set, we can use the SISMEMBER command:
Redis::command('SISMEMBER', ['products', 1]);This will return 1 if the value exists in the set and 0 if it does not.
Sets are an excellent way to store unique data that does not need to be in order or have indexes. For example, if you want to keep a list of users who have liked a post, you can use a set to store their IDs. This will allow you to check whether a user has liked a post. And if you want to sync the data with your database, you can use the SMEMBERS command to retrieve all IDs and then attach them to your post. Another example of set usage is tracking unique users. If you want to track unique users that have visited your website, you can use a set to store their IDs. This will allow you to track unique users without storing their data in your database.
Next, we have sorted sets. They are similar to sets, but they have a score. This allows us to sort the data by score. To store a sorted set, we can use the ZADD command:
$products = Product::query()->limit(100)->get(); foreach ($products as $product) { // The format is ZADD KEY SCORE VALUE Redis::command('ZADD', ['products', $product->price, $product->id]);}This will store our products in a sorted set called products:

And we can retrieve them like this:
$products = Redis::command('ZRANGE', ['products', 0, 10]);This will return the first 10 products from our sorted set:

As you can see, we can retrieve the data in order. This is because sorted sets are sorted by score. We can also retrieve the data in reverse order:
$products = Redis::command('ZREVRANGE', ['products', 0, 10]);This will return the last 10 products from our sorted set.
While this was a simple example, sorted sets are great for storing data that needs to be sorted. A few examples of this are:
Now that we know how to use Redis and what data types it supports, let's take a look at some of the commonly used commands:
The COPY command copies the value of a key to another key. This command works like copy/paste would. In our case, we have visitors stored in a set, which we want to copy as a "snapshot" for processing:

To do this, we can use the COPY command:
// We must watch for the key name Laravel assigns to our cache. In this case `laravel_database_` is neededRedis::command('COPY', ['laravel_database_visitors', 'visitors_snapshot']);Once we run this command, we can see that we have a new key called visitors_snapshot:

The PERSIST command removes the expiration from a key. This command works like remove expiration would. In our case, we have visitors stored in a set, which we want to remove the expiration from:

To do this, we can use the PERSIST command:
Redis::command('PERSIST', ['laravel_database_visitors']);Once we run this command, we can see that the expiration has been removed:

This is useful if you accidentally set an expiration on a key that was hard to calculate and want to keep forever. Mistakes happen, and this command can help you fix them.
The SORT command sorts the elements in a list, set, or sorted set. This command works like sort would. In our case, we have visitors stored in a set, which we want to sort:

To do this, we can use the SORT command:
Redis::command('SORT', ['visitors', ['sort' => 'desc', 'by' => 'ALPHA']])Once we run this command, we can see that the set has been sorted:

This command returns the sorted elements but does not change the original set. It is helpful to sort a list and return the sorted elements.
The TTL command returns the time to live for a key. This command works like get expiration would. In our case, we have visitors stored in a set, which we want to check the expiration for:
To do this, we can use the TTL command:
Redis::command('TTL', ['visitors']);Once we run this command, we can see that the expiration is set to 600 seconds:

This is useful to check how long a key will be valid. For example, if you want to cache a value for 10 minutes, you can use the TTL command to check how long you will have the value cached.
In case you want to check if a key exists, you can use the EXISTS command:
Redis::command('EXISTS', ['visitors']);This returns a simple true/false (or 1/0) value. This is useful to ensure a key exists before you try to retrieve or do anything with it (mainly if you use Redis::command()).
The next command is INCR, which increments the value of a key by 1. This command works like ++ would. In our case, we can track the number of views for our posts:
Redis::command('INCR', ['views:post:1']);This will increment the value of views:post:1 by 1, and we can see that in RedisInsight:

You can use this command to track the number of views for your posts, products, or any other data that you want to track.
Note: It is safe to assume that if we have INCR, we also have DECR, which decrements the value of a key by 1. This command works like -- would.
The FLUSHALL command removes all keys from all databases. This command works like delete all would. In our case, we can clear all keys from Redis:
Redis::command('FLUSHALL');Once this runs, our Redis storage will be empty. This is useful if you want to clear all Redis storage (for example, for testing purposes locally). We do not recommend using this in production as it will remove all databases' keys, which might cause issues!
The DEL command removes one or more keys from Redis. This command works like delete would. In our case, we can clear a specific key from Redis:
Redis::command('DEL', ['visitors']);This will delete our visitors key from Redis. This is useful if you want to clear a specific key from Redis to free up some space or to make sure that the key does not exist anymore.
The PING command checks if Redis is running. This command works like ping would. In our case, we can check if Redis is running:
Redis::command('PING');Once this command runs, we should get a fun response:

This is useful to check if Redis is running before you try to do anything with it. For example, you can add this to your scheduler to check each minute if Redis is running, and if not - send an alert to your team.
As with everything - each of these commands can be used in different ways and with other parameters, and while we showed you simple examples - you might want to read on the documentation to see how you can use them in your application.
While Redis allows you to run multiple commands individually, it will create bottlenecks. It may not be noticeable at first, but as your application grows, you will notice that Redis is slowing down your application. This is where pipelines come in:
Pipelines are a way to batch multiple commands into one request. This means that instead of sending ten, twenty, or even a hundred requests to Redis - you can send one request with all the commands. This will speed up the process as it will not have to wait for each command to finish and will not have to wait until you re-connect to Redis again. Here's what it looks like:
Note: We will use Laravel Benchmark to show you the difference between pipelines and normal commands.
Running the benchmark with normal commands:
use Illuminate\Support\Benchmark; Benchmark::dd(function () { for ($i = 0; $i < 100; $i++) { Redis::command('set', ['key:' . $i, $i]); }}, 10);This tells us that it took 5.169ms to run 100 commands. Increasing to 1000 commands - it took 23.363ms. Now, let's try to run the same benchmark with pipelines:
use Illuminate\Support\Benchmark; Benchmark::dd(function () { Redis::pipeline(function ($pipe) { for ($i = 0; $i < 100; $i++) { $pipe->set('key:' . $i, $i); } });}, 10);This time, it took 0.735ms to run 100 commands and 4.021ms to run 1000 commands. This is a huge difference! And while it might not be noticeable at first - it will be apparent when you start to scale your application. We recommend you use pipelines as soon as you do multiple actions in Redis.
When dealing with Redis, we must remember that it can fail, too. Just like our MySQL database can fail. And when it does - we need to be prepared. We don't want to have Redis quit on us while processing a data file, right? This is where transactions come in. They are very similar to Laravel DB::transaction():
Redis::transaction(function ($pipe) { $pipe->set('key', 'value'); $pipe->set('key2', 'value2');});When Redis receives this command, it runs atomic execution. This means that it will execute all commands or none of them, just like DB::transaction() would. This is great if you are writing a lot of data or sending commands that could fail, as you will prevent data corruption.
Since we know that Redis is an in-memory database, we should know that any server restart or service crash will cause us to lose all the data. This is why we need to protect it! Now, there are a few ways to do this:
Each of these has advantages and disadvantages. To choose the right one, read the Redis Website Documentation as it fully lists everything.
Since Redis stores the data in memory, you must be careful with how much data you store. If you keep too much data, Redis will only accept data (and reply with errors if you try to store more data). You can still access the data stored via read commands, but adding a new one - will not be possible.
Of course, remember that usually, Redis is only one of the things running on your server, so you might encounter more issues with different services. Keep that in mind and set reasonable limits for your Redis instance. To do so, follow this guide.
We have talked a lot about the theory of Redis. But what good is the theory without real-life practice? With this, we encourage you to look at your project and try to implement Redis in a few cases:
With this, we encourage you to see how Redis can be used in your project. It is okay if you don't need it, but knowing your options and how to use them is always good.
.png-674b5251359fd.jpg)
.png-674b519272356.jpg)
.png-674b525e9d6ad.jpg)
.png-674b52368b309.jpg)
